I’ve run into some situations when the build fails, perhaps because some processes don’t finish, and even setting a timeout doesn’t make the Jenkins job fail.
So, to fix this problem, I used try .. catch and error to make my Jenkins job failed, hopes this also helps you.
I’m just documenting to myself that it was solved by following.
When I want to integrate the ESlint report with Jenkins. I encourage a problem
That is eslint-report.html display different with it on my local machine, and I also log to Jenkins server and grab the eslint-report.html to local, it works well.
I used HTML Publisher plugin to display the HTML report, but only the ESlint HTML report has problems other report work well, so I guess this problem may be caused by Jenkins.
To better manage the branches on Git(I sued Bitbucket), integration with CI tool, Artifactory, and automation will be more simple and clear.
For example, good unified partition naming can help the team easily find and integrate without special processing. Therefore, you should unify the partition naming rules for all repositories.
When you do CI with JFrog Artifactory when you want to download the entire folder artifacts, but maybe your IT doesn’t enable this function, whatever some seasons.
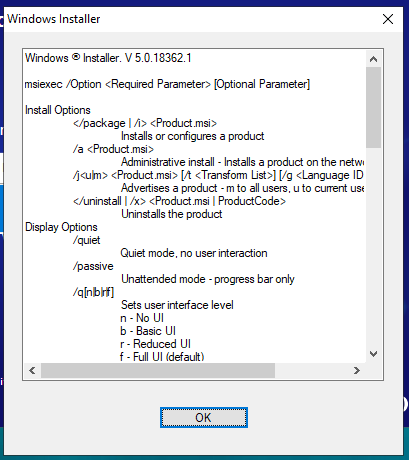
Today I am having a problem where the Windows installer I created is not installing, and the following Windows installer box pops up.
But it works well in the previous build, and I didn’t make any code changes. It is strange, actually fix this problem is very easy but not easy to find.
test { useJUnitPlatform() exclude '**/**IgnoreTest.class'// 如果有 test case 不通过,如有必要可以通过这样忽略掉 finalizedBy jacocoTestReport // report is always generated after tests run }
jacocoTestReport { dependsOn test // tests are required to run before generating the report reports { xml.enabled true csv.enabled false html.destination file("${buildDir}/reports/jacoco") } }
执行测试,生成代码覆盖率报告
然后执行 gradle test 就可以了。之后可以可以在 build\reports\jacoco 目录下找到报告了。
When you use Jenkins multibranch pipeline, you may want to have different default parameters settings for defferent branches build.
For example:
For develop/hotfix/release branches, except regular build, you also want to do some code analyzes, like code scanning, etc. For other branches, like feature/bugfix or Pull Request that you just want to do a regular build.
So you need to have dynamic parameter settings for your multibranch pipeline job.
Today, when I tried to upgrade my team’s Jenkins server from Jenkins 2.235.1 to Jenkins 2.263.3, I met a problem that can not launch the Windows agent.
[2021-01-29 23:50:40] [windows-agents] Connecting to xxx.xxx.xxx.xxx <!-- more --> Checking if Java exists java -version returned 11.0.2. [2021-01-29 23:50:40] [windows-agents] Installing the Jenkins agent service [2021-01-29 23:50:40] [windows-agents] Copying jenkins-agent.exe ERROR: Unexpected error in launching an agent. This is probably a bug in Jenkins Also: java.lang.Throwable: launched here at hudson.slaves.SlaveComputer._connect(SlaveComputer.java:286) at hudson.model.Computer.connect(Computer.java:435) at hudson.slaves.SlaveComputer.doLaunchSlaveAgent(SlaveComputer.java:790) ... ... at java.lang.Thread.run(Thread.java:748) java.lang.NullPointerException at hudson.os.windows.ManagedWindowsServiceLauncher.launch(ManagedWindowsServiceLauncher.java:298)
[2021-01-30 23:53:40] [windows-agents] Connecting to xxx.xxx.xxx.xxx Checking if Java exists java -version returned 11.0.2. [2021-01-30 23:53:47] [windows-agents] Copying jenkins-agent.xml [2021-01-30 23:53:48] [windows-agents] Copying agent.jar [2021-01-30 23:53:48] [windows-agents] Starting the service ERROR: Unexpected error in launching an agent. This is probably a bug in Jenkins org.jinterop.dcom.common.JIException: Unknown Failure at org.jvnet.hudson.wmi.Win32Service$Implementation.start(Win32Service.java:149) Caused: java.lang.reflect.InvocationTargetException at sun.reflect.GeneratedMethodAccessor219.invoke(Unknown Source) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.kohsuke.jinterop.JInteropInvocationHandler.invoke(JInteropInvocationHandler.java:140) Also: java.lang.Throwable: launched here
Then change jenkins-agent.exe.config file. remove or comment out this line <supportedRuntime version="v2.0.50727" /> as below
also do this for jenkins-slave.exe.config in case it also exists.
<configuration> <runtime> <!-- see http://support.microsoft.com/kb/936707 --> <generatePublisherEvidenceenabled="false"/> </runtime> <startup> <!-- this can be hosted either on .NET 2.0 or 4.0 --> <!-- <supportedRuntime version="v2.0.50727" /> --> <supportedRuntimeversion="v4.0" /> </startup> </configuration>
Then try to Launch agent.
If it still does not work and has this error message “.NET Framework 2.0 or later is required on this computer to run a Jenkins agent as a Windows service”, you need to upgrade your .NET Framework.