
最近的文章
申请通过了,Anthropic 免费送了我 6 个月 Claude Max
申请 Anthropic 开源开发者计划通过了,拿到了 6 个月 Claude Max 20x 的免费使用权。聊聊申请条件、为什么能通过,以及这些年维护开源项目的一些感受。

用 no-ai-slop 去掉你文章里的 AI 味
最近写文章越来越多用 AI 帮忙,但写完总感觉哪里不对——那味道太冲了。Peter Yang 做了一个叫 no-ai-slop 的开源 skill,专门识别和去除英文写作里的 AI 套话模式,但没有中文版。我把它翻译并适配成了中文版本,支持 20 多种中文 AI 套话模式的检测和编辑。如果你也在用 AI 写公众号或技术文章,这个工具应该能帮你。

从吹到黑:我为什么不再推荐 GitHub Copilot?
最近我对 GitHub Copilot 的态度发生了一次比较大的变化:从原来的"吹"变成了现在的"黑"。在对比了 Claude Code 之后,我发现 Copilot 在跨仓库支持、高级工程师意识等方面存在明显不足,已经让我不愿意再和它讨论问题了。
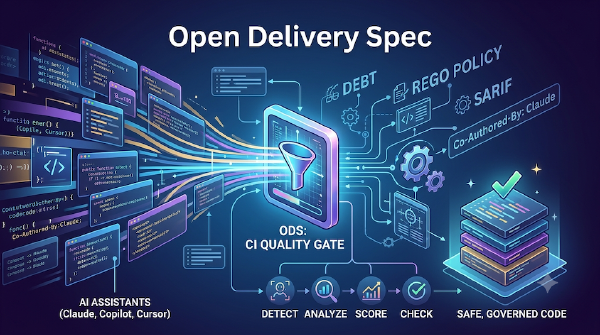
Open Delivery Spec:我为 AI 写的代码做了一道 CI 质量门
过去几个月我业余做了一个开源组织 Open Delivery Spec (ODS)。起因是 AI 生成的代码越来越多,但团队缺乏可靠的治理手段。本文基于项目真实现状,记录思路、进展与边界,不做任何夸大。

Conventional Branch 1.1.0 发布,正式支持 AI Coding Agent 分支前缀
Conventional Branch 规范迎来首次重大更新。1.1.0 版本新增了 AI Coding Agent 分支前缀支持(ai/、copilot/、cursor/、claude/、codex/),同时提供了 machine-readable 的 spec.json 和 agent 注册表,让规范不仅面向人,也面向工具。

Jenkinsfile Lint 1.5.0 发布:不需要 Jenkins 服务器的 Standalone 模式
之前 jenkinsfilelint 需要连接一个可用的 Jenkins 服务器才能做语法校验。现在 v1.5.0 新增了 standalone 模式,只需要有 Docker,就能在本地启动一个最小 Jenkins 环境来验证 Jenkinsfile 语法。这篇文章详细介绍这个模式的实现思路和用法。

你的仓库里,哪些代码是 AI 写的?现在有工具能管住了
Claude Code 等 AI 工具默认会往提交里塞签名,很多人根本没注意到。Commit Check v2.11.0 引入 AI 归属治理,一行配置即可在 CI 层面拒绝带 AI 签名的提交。本文也聊聊这个功能的边界,以及这半年 Commit Check 解决的其他几个痛点。

原本只想提个文档 PR,结果项目进了 Jenkins 官方组织
我写了一个验证 Jenkinsfile 的小工具,原本只是想让它出现在 Jenkins 官方的开发工具列表里。结果 Jenkins 维护者提议:不如直接把项目转进 jenkinsci 组织?这篇文章记录了从 PR 到 transfer 再到官方博客的完整过程,包括中间踩的一个很有意思的坑。

从 Demo 到生产:Agentic Application 的 8 层架构
本文从 Agent 边界设计、Tool Engineering、可观测性、评估体系、Memory 分层、Human-in-the-Loop、成本控制和安全八个维度,拆解一套面向企业落地的 Agentic Application 架构思路。

Conventional Branch 有了自己的域名:conventionalbranch.org
Conventional Branch 项目网站正式从 conventional-branch.github.io 迁移到 conventionalbranch.org。从去年用户提议到今年最终落地,聊聊域名迁移背后那些犹豫、踩坑和思考。

cpp-linter-hooks:C/C++ 项目最完整的 pre-commit 方案
pre-commit 生态里 C/C++ 的工具一直比较薄弱。cpp-linter-hooks 是目前唯一同时支持 clang-format 和 clang-tidy 的 pre-commit hook,还内置了编译数据库自动检测、版本锁定、自动修复等实用功能。本文介绍它的用法和设计思路。

Conventional Branch 官方 Skill 来了,安装只需一行命令
有用户提 Issue 希望 Conventional Branch 能提供官方 Agent Skill,我觉得这个需求很合理。当天就把它做了出来,现在通过 npx skills add 一行命令就能下载使用。恰逢本周项目也突破了 100 个 Star,一并聊聊。
申请通过了,Anthropic 免费送了我 6 个月 Claude Max
申请 Anthropic 开源开发者计划通过了,拿到了 6 个月 Claude Max 20x 的免费使用权。聊聊申请条件、为什么能通过,以及这些年维护开源项目的一些感受。
用 no-ai-slop 去掉你文章里的 AI 味
最近写文章越来越多用 AI 帮忙,但写完总感觉哪里不对——那味道太冲了。Peter Yang 做了一个叫 no-ai-slop 的开源 skill,专门识别和去除英文写作里的 AI 套话模式,但没有中文版。我把它翻译并适配成了中文版本,支持 20 多种中文 AI 套话模式的检测和编辑。如果你也在用 AI 写公众号或技术文章,这个工具应该能帮你。
从吹到黑:我为什么不再推荐 GitHub Copilot?
最近我对 GitHub Copilot 的态度发生了一次比较大的变化:从原来的"吹"变成了现在的"黑"。在对比了 Claude Code 之后,我发现 Copilot 在跨仓库支持、高级工程师意识等方面存在明显不足,已经让我不愿意再和它讨论问题了。
Open Delivery Spec:我为 AI 写的代码做了一道 CI 质量门
过去几个月我业余做了一个开源组织 Open Delivery Spec (ODS)。起因是 AI 生成的代码越来越多,但团队缺乏可靠的治理手段。本文基于项目真实现状,记录思路、进展与边界,不做任何夸大。
Conventional Branch 1.1.0 发布,正式支持 AI Coding Agent 分支前缀
Conventional Branch 规范迎来首次重大更新。1.1.0 版本新增了 AI Coding Agent 分支前缀支持(ai/、copilot/、cursor/、claude/、codex/),同时提供了 machine-readable 的 spec.json 和 agent 注册表,让规范不仅面向人,也面向工具。
Jenkinsfile Lint 1.5.0 发布:不需要 Jenkins 服务器的 Standalone 模式
之前 jenkinsfilelint 需要连接一个可用的 Jenkins 服务器才能做语法校验。现在 v1.5.0 新增了 standalone 模式,只需要有 Docker,就能在本地启动一个最小 Jenkins 环境来验证 Jenkinsfile 语法。这篇文章详细介绍这个模式的实现思路和用法。
你的仓库里,哪些代码是 AI 写的?现在有工具能管住了
Claude Code 等 AI 工具默认会往提交里塞签名,很多人根本没注意到。Commit Check v2.11.0 引入 AI 归属治理,一行配置即可在 CI 层面拒绝带 AI 签名的提交。本文也聊聊这个功能的边界,以及这半年 Commit Check 解决的其他几个痛点。
原本只想提个文档 PR,结果项目进了 Jenkins 官方组织
我写了一个验证 Jenkinsfile 的小工具,原本只是想让它出现在 Jenkins 官方的开发工具列表里。结果 Jenkins 维护者提议:不如直接把项目转进 jenkinsci 组织?这篇文章记录了从 PR 到 transfer 再到官方博客的完整过程,包括中间踩的一个很有意思的坑。
从 Demo 到生产:Agentic Application 的 8 层架构
本文从 Agent 边界设计、Tool Engineering、可观测性、评估体系、Memory 分层、Human-in-the-Loop、成本控制和安全八个维度,拆解一套面向企业落地的 Agentic Application 架构思路。
Conventional Branch 有了自己的域名:conventionalbranch.org
Conventional Branch 项目网站正式从 conventional-branch.github.io 迁移到 conventionalbranch.org。从去年用户提议到今年最终落地,聊聊域名迁移背后那些犹豫、踩坑和思考。
cpp-linter-hooks:C/C++ 项目最完整的 pre-commit 方案
pre-commit 生态里 C/C++ 的工具一直比较薄弱。cpp-linter-hooks 是目前唯一同时支持 clang-format 和 clang-tidy 的 pre-commit hook,还内置了编译数据库自动检测、版本锁定、自动修复等实用功能。本文介绍它的用法和设计思路。
Conventional Branch 官方 Skill 来了,安装只需一行命令
有用户提 Issue 希望 Conventional Branch 能提供官方 Agent Skill,我觉得这个需求很合理。当天就把它做了出来,现在通过 npx skills add 一行命令就能下载使用。恰逢本周项目也突破了 100 个 Star,一并聊聊。
申请通过了,Anthropic 免费送了我 6 个月 Claude Max
申请 Anthropic 开源开发者计划通过了,拿到了 6 个月 Claude Max 20x 的免费使用权。聊聊申请条件、为什么能通过,以及这些年维护开源项目的一些感受。
用 no-ai-slop 去掉你文章里的 AI 味
最近写文章越来越多用 AI 帮忙,但写完总感觉哪里不对——那味道太冲了。Peter Yang 做了一个叫 no-ai-slop 的开源 skill,专门识别和去除英文写作里的 AI 套话模式,但没有中文版。我把它翻译并适配成了中文版本,支持 20 多种中文 AI 套话模式的检测和编辑。如果你也在用 AI 写公众号或技术文章,这个工具应该能帮你。
从吹到黑:我为什么不再推荐 GitHub Copilot?
最近我对 GitHub Copilot 的态度发生了一次比较大的变化:从原来的"吹"变成了现在的"黑"。在对比了 Claude Code 之后,我发现 Copilot 在跨仓库支持、高级工程师意识等方面存在明显不足,已经让我不愿意再和它讨论问题了。
Open Delivery Spec:我为 AI 写的代码做了一道 CI 质量门
过去几个月我业余做了一个开源组织 Open Delivery Spec (ODS)。起因是 AI 生成的代码越来越多,但团队缺乏可靠的治理手段。本文基于项目真实现状,记录思路、进展与边界,不做任何夸大。
Conventional Branch 1.1.0 发布,正式支持 AI Coding Agent 分支前缀
Conventional Branch 规范迎来首次重大更新。1.1.0 版本新增了 AI Coding Agent 分支前缀支持(ai/、copilot/、cursor/、claude/、codex/),同时提供了 machine-readable 的 spec.json 和 agent 注册表,让规范不仅面向人,也面向工具。
Jenkinsfile Lint 1.5.0 发布:不需要 Jenkins 服务器的 Standalone 模式
之前 jenkinsfilelint 需要连接一个可用的 Jenkins 服务器才能做语法校验。现在 v1.5.0 新增了 standalone 模式,只需要有 Docker,就能在本地启动一个最小 Jenkins 环境来验证 Jenkinsfile 语法。这篇文章详细介绍这个模式的实现思路和用法。
你的仓库里,哪些代码是 AI 写的?现在有工具能管住了
Claude Code 等 AI 工具默认会往提交里塞签名,很多人根本没注意到。Commit Check v2.11.0 引入 AI 归属治理,一行配置即可在 CI 层面拒绝带 AI 签名的提交。本文也聊聊这个功能的边界,以及这半年 Commit Check 解决的其他几个痛点。
原本只想提个文档 PR,结果项目进了 Jenkins 官方组织
我写了一个验证 Jenkinsfile 的小工具,原本只是想让它出现在 Jenkins 官方的开发工具列表里。结果 Jenkins 维护者提议:不如直接把项目转进 jenkinsci 组织?这篇文章记录了从 PR 到 transfer 再到官方博客的完整过程,包括中间踩的一个很有意思的坑。
从 Demo 到生产:Agentic Application 的 8 层架构
本文从 Agent 边界设计、Tool Engineering、可观测性、评估体系、Memory 分层、Human-in-the-Loop、成本控制和安全八个维度,拆解一套面向企业落地的 Agentic Application 架构思路。
Conventional Branch 有了自己的域名:conventionalbranch.org
Conventional Branch 项目网站正式从 conventional-branch.github.io 迁移到 conventionalbranch.org。从去年用户提议到今年最终落地,聊聊域名迁移背后那些犹豫、踩坑和思考。
cpp-linter-hooks:C/C++ 项目最完整的 pre-commit 方案
pre-commit 生态里 C/C++ 的工具一直比较薄弱。cpp-linter-hooks 是目前唯一同时支持 clang-format 和 clang-tidy 的 pre-commit hook,还内置了编译数据库自动检测、版本锁定、自动修复等实用功能。本文介绍它的用法和设计思路。
Conventional Branch 官方 Skill 来了,安装只需一行命令
有用户提 Issue 希望 Conventional Branch 能提供官方 Agent Skill,我觉得这个需求很合理。当天就把它做了出来,现在通过 npx skills add 一行命令就能下载使用。恰逢本周项目也突破了 100 个 Star,一并聊聊。