I am Xianpeng, a build engineer. Today, I am going to share with you three Jenkins Practice.
I will talk about Configuration as code, followed up with shared libraries, and then Multi-Branch Pipeline in the end.
Configuration as Code
What is Configuration as Code?
Configuration as code (CAC) is an approach that managing configuration resources in a bitbucket repository
What are the benefits?
First, Jenkins Job Transparency
To those who have experience with Bamboo jobs, you know how hard it is to grasp the logic from the GUI, this is especially true to people who don’t know the tools very well. So, when we migrated Bamboo jobs to Jenkins, we decided to use Configuration as code, because the code is more readable and very easy for engineers to understand the logic and flow.
Secondly, Traceability
Another drawback of configuring Jenkins Jobs through GUI is that it cannot trace the history and see who did what. The ability to see who made changes is very very important for some critical Jenkins jobs, such as build jobs. With Configuration as code, we treat the Jenkins job code the same way as other application code, the benefits are not only on traceability-wise, but also the ability to roll-back to a specific version if needed.
Thirdly, Quick Recovery
Using Configuration as code has another benefit, which is the ability to quickly recover Jenkins’s job upon hardware issues. However, if Jenkins Job is configured through GUI, when the server that host the Jenkins corrupted, you might at risk of losing everything relates to Jenkins. So, from the business continuity perspective, it is also suggesting us to use configuration as code.
Jenkins Shared Libraries
Just like writing any application code, that we need to create functions, subroutines for reuse and sharing purpose. The same logic applies to the Jenkins configuration code. Functionalities such as sending emails, printing logs, deploying the build to FTP/Artifactory can be put into Jenkins Shared Libraries. Jenkins Shared Libraries is managed in Bitbucket.
So, let’s take a look, …
xshen@localhost MINGW64 /c/workspace/cicd/src/org/devops (develop) |
As you can see, these groovy files are so-called shared libraries that complete works such as sending emails, git operations, updating opensource and so on.
So, it is becoming very clear why we want to use shared libraries because it can reduce duplicate code.
It is also easier to maintain because instead of updating several places, we just need to update the shared libraries if any changes required. The last but not least, it encourages reuse and sharing cross teams. For example, the shared libraries I created are also used other team.
Multi-branch pipeline
Next, Multi-branch pipeline. Some of you may have seen the same diagram like this.
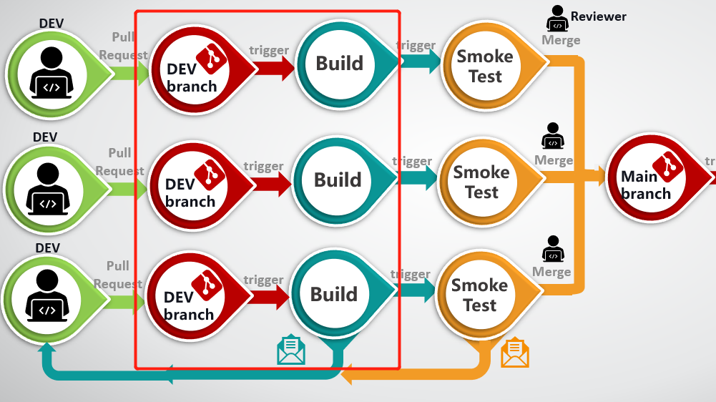
In this picture, the pull request will trigger an automatic build, which is very helpful to engineers because their changes will not be merged to the main branch unless it passes the build test and smoke test.
So, I will share more detailed information here with you.
The thing works behind the scene is called Jenkins Multi-branch Pipeline. Before getting into the details, let’s first see what it looks like.
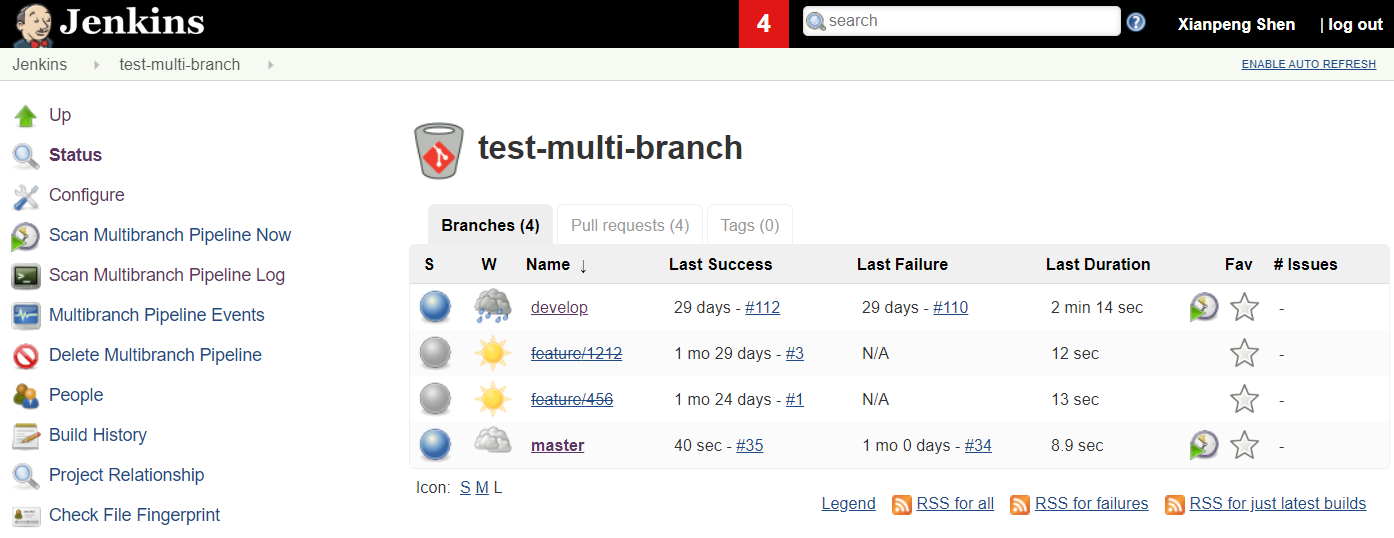
Note: If your branch or Pull Request has been deleted, the branch or Pull Request will either be removed from the multi-branch Job or show a crossed-out status as shown above, this depending on your Jenkins setting.
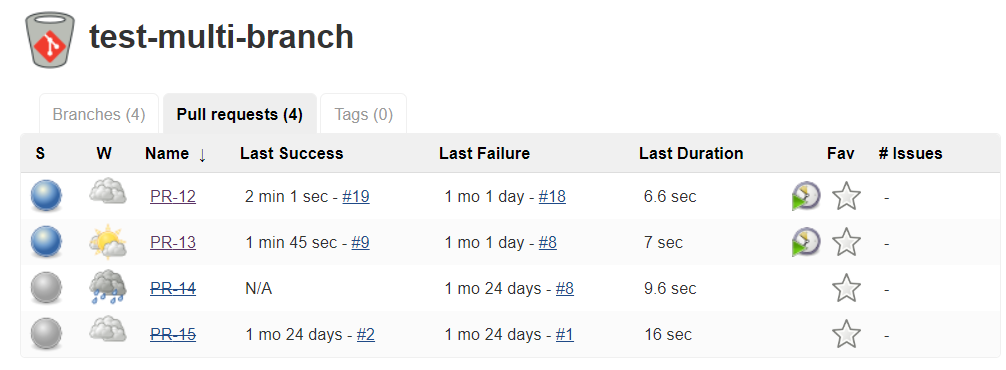
So, as you can see from this page, there are multi Jenkins jobs. That is because for each bugfix or feature branch in Bitbucket, this multi-branch pipeline will automatically create a Jenkins job for them.
So, when developers complete their works, they can use these Jenkins jobs to create official build by themselves without the need of involving a build engineer. However, this was not the case in the past. At the time that we did not have these self-service jobs, developers always ask help from me, the build engineer to create a build for them. We have around twenty U2 developers in the team, you can image the efforts needed to satisfy these requirements.
So, I just covered the first benefit of this multi-branch pipeline, which creates a self-service for the team, save their time, save my time.
Another benefit of this self-service build and install is that our main branch will be more stable and save us from the time spent on investigating whose commit was problematic because only changes passed build, install and smoke test will be merged into the main branch.
Now, you may wonder the value of this work, like how many issues have been discovered by this auto build and install test.
Taking our current development as an example, there were about 30 pull requests merged last month, and six of them were found has built problems on some platforms.
As you all know, the cost of quality will be very low if we can find issues during the development phase, rather than being found by QA, Support or even customer.
Please comments in case you have any questions.